

This article is part of “AI education”, a series of posts that review and explore educational content on data science and machine learning.
Today, deep learning might seem like a manifestation of the saying by British science fiction writer Arthur C. Clarke: “Any sufficiently advanced technology is indistinguishable from magic.” In the past years, deep learning has proven to be capable of creating realistic images of non-existing people, recognizes faces and voice commands, synthesize voice that sounds almost natural, and (pretend to) understand natural language.
The remarkable feats of deep learning make it look magical and out of reach. Yet, at heart, any deep learning model is just a combination of simple mathematical components. In this post, I will (try to) show you how deep learning works by building it piece by piece.
The zoomed-out view of deep neural networks
Deep learning algorithms use different configurations of deep neural networks, architectures that most books and articles describe as a rough imitation of biological brains (the analogy surely doesn’t help simplify the concept, does it?).
A deep neural network is composed of several layers of artificial neurons stacked on top of each other. Each neuron is connected to several neurons in the next layer. Input data goes through the network, processed by neurons in each layer and passed on to the next layer until it reaches the output layer. This is how deep learning models classify images, transform voice to text, predict stock prices, and perform many other complicated tasks.

When seen from far, deep neural networks can look daunting. It might seem like alchemy, turning one type of information into a completely different type of information.
But up close, things become much simpler.
The linear transformation
The smallest component of the deep neural network is the artificial neuron. Every neuron is a function for a linear transformation, a very simple operation that you’ve learned in high school. In a nutshell, a linear transformation modifies an input number by multiplying it by one or more weights and adding a bias value. The weights and bias are also called the parameters of the neuron.
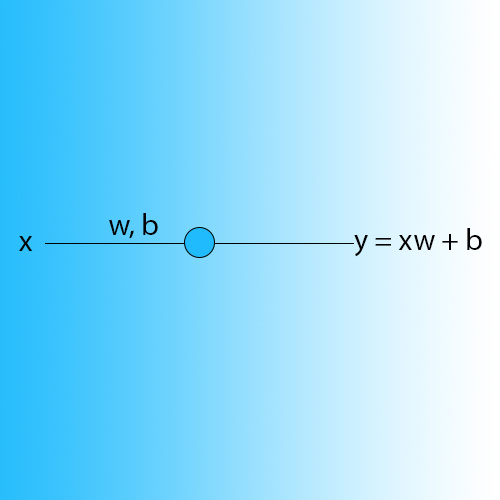
In fact, the simplest neural network is composed of a single neuron that performs a single linear transformation on one of more input values.
For example, to create a simple neuron that converts temperature measures from Celsius to Fahrenheit, we set its parameters to the following: w = 1.8 and b = 32.

Teaching artificial neurons unknown functions
In the case of Celsius-to-Fahrenheit conversion neuron, we already knew the formula for the transformation. But we want to use deep learning to solve problems where we only have observations and don’t know the values of the parameters of the underlying function.
For example, imagine we want to create a machine learning model to forecast sales for a vending machine that sells bottled water at a museum. We have registered the number of people who visited the museum, the weather temperature, and the number of bottles sold for a period of 50 days. Here’s a table with ten sample observations:

When plotted on a chart, the data looks like this:

As the two charts show, both the number of people visiting the museum and the temperature affect the number of bottles sold. Now, we want to see if we can train an artificial neuron to forecast sales for the vending machine.
We’ll start with a neuron that takes a single input, the number of people visiting the museum. (We’ll forgo the bias in this case for simplicity’s sake, but we also know that we don’t need it because we’ll sell zero bottles if no one visits the museum.)
We don’t know the neuron’s weight, so we’ll start with a random value, say 0.5. We run our first data point (105) through the neuron and we obtain the following result:
Sales = 105*0.5 = 52.5
The real number of bottles sold was 21, so we’re way off mark and need to adjust the weight. This is where the learning happens.
Measuring errors in neural networks
Neural networks learn by making predictions, measuring errors, and adjusting weights. In the last step, our neuron predicted that we would sell 52 bottles, but in reality we had sold 21, so our model missed the goal by 31. This is our model’s error.
Looking at our results, we can quickly see that if we adjust the weight to 0.21, it will predict sales accurately (0.2 * 105 = 21). But the, if we run the next row of data through the neuron (Num people = 90, Sales = 21), our model’s prediction will be the following:
Sales = 0.21 * 121 = 18.9
Now our prediction is off by about 2. We could retune the weight to 0.23 accommodate this observation, but then our model would err on the first observation. Therefore, the goal of learning in neural networks is to find a systematic way to tune the weights to minimize the overall error.
Gradient descent, loss functions, and learning rates

When we want to train our neural network on several observations, we can never tune its parameters to a single example. That would cause overfitting, where a network performs very well on a limited number of inputs but terribly on others. Instead, we want the weights to be at an optimal point where they would cause the minimum overall error.
To find that optimal configuration, we will use gradient descent, a learning algorithm in which we continuously measure the accuracy of our model and make small adjustments until we reach the minimum error.
The first step of gradient descent is to measure the overall accuracy of our model. To do this, we predict sales for every observation by multiplying the number of visitors by our initial weight. We then subtract the observed sales from our prediction to calculate the error. We’re also going to keep track of the squared error, which is basically the error times itself. Squared error prevents negative and positive errors from cancelling each other out. Here’s a sample of what our predictions look like with the starting weight (0.5).

When training a neural network, it is important to have a single metric to measure the overall performance of the model. This metric is called the loss function. For our current problem, we will use the mean squared error (MSE), which is the sum of the squared errors divided by the number of observations. Our current MSE is 671.58. The goal of our training is to minimize the loss function.
So, we now know that our weight is much larger than it should be. But how do we decide whether we should reduce or increase the weight? A simple (and inefficient) way to find out is to make small moves in both directions and keep the one that reduces the MSE.
The amount by which we adjust our weight is called the learning rate. Choosing the right learning rate for network is very important. If the learning rate is too large, you will overshoot, which means you’ll skip the optimal configuration with a single step. If the learning rate is too small, it’ll take very long to reach the optimal point.
In the case of our problem, we’ll choose 0.01 as learning rate. First, we add 0.01 to the weight, setting it to 0.51. After recalculating the predictions, we see that our mean squared error now stands at 723.72, which is larger than before.
Next, we reduce 0.01 from the weight, setting it to 0.49. After reprocessing the calculations, our MSE now stands at 621.41. This shows that the right direction is to continue to reduce the weight.
When we go through the entire training data once and make adjustments to the weights of our neural network, we’ve completed one epoch of training. The full training of the neural network will span over many epochs.
Epoch and learning rate are called hyperparameters, which means you must set them before training your machine learning model. The weight are the learned parameters, because they’re tuned during the training.
After going through several more epochs, we realize that when the weight of our artificial neuron is set to 0.24, our mean squared error is at its lowest point, and reducing it further will cause the MSE to increase.

We have finished training our machine learning model. In deep learning lingo, we say that our network as converged when it reaches its lowest possible error.
Note that this a simplified explanation and is not the most efficient way to train the network. There are several tricks that can help prevent redundant calculations (such as finding whether reducing or adding the learning rate will reduce the error) and speed up the learning process (such as dynamically changing the learning rate). But the fundamentals remain the same: predict values, measure error, adjust weights.
Adding another input
By just using the number of visitors, we were able to train the neuron to make a decent prediction of the number of bottles our vending machine would sell. If we plot our machine learning model against our previous observations, we’ll see that the line passes nicely through the middle of our data.

But as we saw in the earlier chart, there’s also a correlation between temperature and the number of bottles sold. Therefore, if we integrate the temperature into our machine learning model, it should improve its performance.
Adding temperature to our artificial neuron is as simple as adding another pair of weights and inputs. Our machine learning model will now be represented by the following formula:
sales = visitors * w0 + temperature * w1
There are nuances to training a machine learning model with more than one input. You don’t want to update all weights by the same amount. The training process, however, is not different from what we saw in the previous section: We start with random weights, predict outcomes, compare to the ground truth, and adjust our weights.
At the end of the training, you’ll have a model that performs much better because it now factors that we have about our problem. The machine learning model will not reach perfect accuracy, because in reality, there are many other factors that we haven’t included and many that we can’t predict (such as a sudden power outage that shuts down the museum and the vending machine for an entire day). But our predictions come within a fair range of reality.
We can now know in advance whether our vending machine will run out of bottled water based on tomorrow’s weather forecast and the number of tickets sold online.
Adding more layers
While we explored the fundamental workings of artificial neurons and neural networks, nothing of what we have done until now is deep learning. In fact, what we created is a simple linear regression model, an old but very effective machine learning tool. Deep learning shows its true power when you put several of these artificial neurons together and stack them on top of each other in multiple layers (go back to the zoomed-out image at the beginning of this article, which you’ve probably seen countless times.)
But why would we want to pack several artificial neurons together? Because the world is rarely linear in nature and can’t be modeled with a single neuron. Think of a computer vision task, such as classifying images of handwritten digits. There are innumerable ways a single digit can be represented on an array of pixels, and however you tune the weights of your neuron, you’ll never be able to create a fair representation of the each of the digit classes.

When stacked on top of each other, artificial neurons can develop complex, non-linear models of their problem space. Here’s a simplified version of how it works.
The simplest neural network contains one hidden layer and an output layer. In the following example, the hidden layer contains two neurons and the output layer contains a single neuron. The structure of the neurons is similar to the single neuron we explored in the last section (with one small difference that we’ll get to in a bit). The neurons in the hidden layer process the input data and pass it on to the neuron in the output layer, which then performs its own linear transformation and produces an output.

Why does this work? For two reasons. First, the weights of each neuron are initialized with different random values. Therefore, when an input goes through the neurons in the hidden layer, they produce different results.
But before the hidden neurons pass on their result to the output layer, they run it through an activation function. Activation functions perform a non-linear transformation on the data and are crucial to helping deep learning models extract complicated patterns from their training data. There various activation functions, but three that are very popular are tanh, sigmoid, and ReLU, depicted below.

Interestingly, the combination of layered neurons and activation functions can accomplish many tasks that are impossible with simple linear machine learning models, including recognizing handwritten digits. By adding more layers and neurons to the deep learning model, you will increase its complexity and enable it to learn even more complicated tasks.
Advanced deep learning concepts
The topics we discussed in this post consist the core of all deep learning systems. But they are just a fraction of the concepts you’ll encounter when exploring deep learning. The past few decades have seen an explosion of new techniques and architectures, all of which make neural networks more efficient and powerful at performing complicated tasks.
What you saw in this post was a neural network composed of dense layers, where each neuron in a lower layer is directly connected to all neurons in the next layer. Another popular architecture is convolution layers, in which neurons perform operations on patches of data from the previous layer. Convolutions are especially suited for processing visual data. Recurrent neural network is another architecture that is suited for sequential data, such as strings of text and audio data. More advanced types of neural networks include long short-term memory (LSTM) and transformers.
There are also a bunch of other techniques that enable neural networks to become more efficient at generalizing what they learn and avoid to overfit to training data. Examples include max pooling and dropout layers.
Hopefully, this post helped you realize that while fascinating, deep learning is not magic and out of reach. It’s the composition of small and simple components that together can perform remarkable feats.






{kind=link}