
If you’ve read about how neural networks are trained, you’ve almost certainly come across the term “gradient descent” before. Gradient descent is the primary method of optimizing a neural network’s performance, reducing the network’s loss/error rate. However, gradient descent can be a little hard to understand for those new to machine learning, and this article will endeavor to give you a decent intuition for how gradient descent operates.
Gradient descent is an optimization algorithm. It’s used to improve the performance of a neural network by making tweaks to the parameters of the network such that the difference between the network’s predictions and the actual/expected values of the network (referred to as the loss) is a small as possible. Gradient descent takes the initial values of the parameters and uses operations based in calculus to adjust their values towards the values that will make the network as accurate as it can be. You don’t need to know a lot of calculus to understand how gradient descent works, but you do need to have an understanding of gradients.
What Are Gradients?
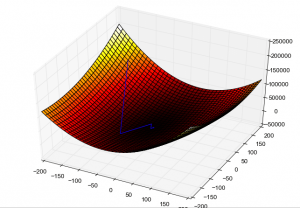
Assume that there is a graph that represents the amount of error a neural network makes. The bottom of the graph represents the points of lowest error while the top of the graph is where the error is the highest. We want to move from the top of the graph down to the bottom. A gradient is just a way of quantifying the relationship between error and the weights of the neural network. The relationship between these two things can be graphed as a slope, with incorrect weights producing more error. The steepness of the slope/gradient represents how fast the model is learning.
A steeper slope means large reductions in error are being made and the model is learning fast, whereas if the slope is zero the model is on a plateau and isn’t learning. We can move down the slope towards less error by calculating a gradient, a direction of movement (change in the parameters of the network) for our model.
Let’s shift the metaphor just slightly and imagine a series of hills and valleys. We want to get to the bottom of the hill and find the part of the valley that represents the lowest loss. When we start at the top of the hill we can take large steps down the hill and be confident that we are heading towards the lowest point in the valley.
However, as we get closer to the lowest point in the valley, our steps will need to become smaller, or else we could overshoot the true lowest point. Similarly, it’s possible that when adjusting the weights of the network, the adjustments can actually take it further away from the point of lowest loss, and therefore the adjustments must get smaller over time. In the context of descending a hill towards a point of lowest loss, the gradient is a vector/instructions detailing the path we should take and how large our steps should be.
Now we know that gradients are instructions that tell us which direction to move in (which coefficients should be updated) and how large the steps we should take are (how much the coefficients should be updated), we can explore how the gradient is calculated.
Calculating Gradients and Gradient Descent Procedure
Gradient descent starts at a place of high loss and by through multiple iterations, takes steps in the direction of lowest loss, aiming to find the optimal weight configuration. Photo: Роман Сузи via Wikimedia Commons, CCY BY SA 3.0 (https://commons.wikimedia.org/wiki/File:Gradient_descent_method.png)
In order to carry out gradient descent, the gradients must first be calculated. In order to calculate the gradient, we need to know the loss/cost function. We’ll use the cost function to determine the derivative. In calculus, the derivative just refers to the slope of a function at a given point, so we’re basically just calculating the slope of the hill based on the loss function. We determine the loss by running the coefficients through the loss function. If we represent the loss function as “f”, then we can state that the equation for calculating the loss is as follows (we’re just running the coefficients through our chosen cost function):
Loss = f(coefficient)
We then calculate the derivative, or determine the slope. Getting the derivative of the loss will tell us which direction is up or down the slope, by giving us the appropriate sign to adjust our coefficients by. We’ll represent the appropriate direction as “delta”.
delta = derivative_function(loss)
We’ve now determined which direction is downhill towards the point of lowest loss. This means we can update the coefficients in the neural network parameters and hopefully reduce the loss. We’ll update the coefficients based on the previous coefficients minus the appropriate change in value as determined by the direction (delta) and an argument that controls the magnitude of change (the size of our step). The argument that controls the size of the update is called the “learning rate” and we’ll represent it as “alpha”.
coefficient = coefficient – (alpha * delta)
We then just repeat this process until the network has converged around the point of lowest loss, which should be near zero.
It’s very important to choose the right value for the learning rate (alpha). The chosen learning rate must be neither too small or too large. Remember that as we approach the point of lowest loss our steps must become smaller or else we will overshoot the true point of lowest loss and end up on the other side. The point of smallest loss is small and if our rate of change is too large the error can end up increasing again. If the step sizes are too large the network’s performance will continue to bounce around the point of lowest loss, overshooting it on one side and then the other. If this happens the network will never converge on the true optimal weight configuration.
In contrast, if the learning rate is too small the network can potentially take an extraordinarily long time to converge on the optimal weights.
Types Of Gradient Descent
Now that we understand how gradient descent works in general, let’s take a look at some of the different types of gradient descent.
Batch Gradient Descent: This form of gradient descent runs through all the training samples before updating the coefficients. This type of gradient descent is likely to be the most computationally efficient form of gradient descent, as the weights are only updated once the entire batch has been processed, meaning there are fewer updates total. However, if the dataset contains a large number of training examples, then batch gradient descent can make training take a long time.
Stochastic Gradient Descent: In Stochastic Gradient Descent only a single training example is processed for every iteration of gradient descent and parameter updating. This occurs for every training example. Because only one training example is processed before the parameters are updated, it tends to converge faster than Batch Gradient Descent, as updates are made sooner. However, because the process must be carried out on every item in the training set, it can take quite a long time to complete if the dataset is large, and so use of one of the other gradient descent types if preferred.
Mini-Batch Gradient Descent: Mini-Batch Gradient Descent operates by splitting the entire training dataset up into subsections. It creates smaller mini-batches that are run through the network, and when the mini-batch has been used to calculate the error the coefficients are updated. Mini-batch Gradient Descent strikes a middle ground between Stochastic Gradient Descent and Batch Gradient Descent. The model is updated more frequently than in the case of Batch Gradient Descent, which means a slightly faster and more robust convergence on the model’s optimal parameters. It’s also more computationally efficient than Stochastic Gradient Descent







{kind=link}