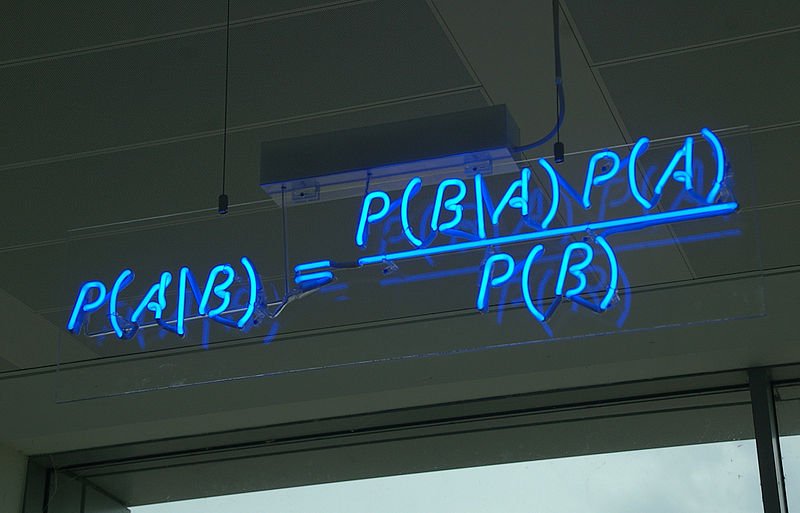
K-Nearest Neighbors is a machine learning technique and algorithm that can be used for both regression and classification tasks. K-Nearest Neighbors examines the labels of a chosen number of data points surrounding a target data point, in order to make a prediction about the class that the data point falls into. K-Nearest Neighbors (KNN) is a conceptually simple yet very powerful algorithm, and for those reasons, it’s one of the most popular machine learning algorithms. Let’s take a deep dive into the KNN algorithm and see exactly how it works. Having a good understanding of how KNN operates will let you appreciated the best and worst use cases for KNN.
An Overview Of KNN

Photo: Antti Ajanki AnAj via Wikimedia Commons, CC BY SA 3.0 (https://commons.wikimedia.org/wiki/File:KnnClassification.svg)
Let’s visualize a dataset on a 2D plane. Picture a bunch of data points on a graph, spread out along the graph in small clusters. KNN examines the distribution of the data points and, depending on the arguments given to the model, it separates the data points into groups. These groups are then assigned a label. The primary assumption that a KNN model makes is that data points/instances which exist in close proximity to each other are highly similar, while if a data point is far away from another group it’s dissimilar to those data points.
A KNN model calculates similarity using the distance between two points on a graph. The greater the distance between the points, the less similar they are. There are multiple ways of calculating the distance between points, but the most common distance metric is just Euclidean distance (the distance between two points in a straight line).
KNN is a supervised learning algorithm, meaning that the examples in the dataset must have labels assigned to them/their classes must be known. There are two other important things to know about KNN. First, KNN is a non-parametric algorithm. This means that no assumptions about the dataset are made when the model is used. Rather, the model is constructed entirely from the provided data. Second, there is no splitting of the dataset into training and test sets when using KNN. KNN makes no generalizations between a training and testing set, so all the training data is also used when the model is asked to make predictions.
How The KNN Algorithm Operates
A KNN algorithm goes through three main phases as it is carried out:
- Setting K to the chosen number of neighbors.
- Calculating the distance between a provided/test example and the dataset examples.
- Sorting the calculated distances.
- Getting the labels of the top K entries.
- Returning a prediction about the test example.
In the first step, K is chosen by the user and it tells the algorithm how many neighbors (how many surrounding data points) should be considered when rendering a judgment about the group the target example belongs to. In the second step, note that the model checks the distance between the target example and every example in the dataset. The distances are then added into a list and sorted. Afterward, the sorted list is checked and the labels for the top K elements are returned. In other words, if K is set to 5, the model checks the labels of the top 5 closest data points to the target data point. When rendering a prediction about the target data point, it matters if the task is a regression or classification task. For a regression task, the mean of the top K labels is used, while the mode of the top K labels is used in the case of classification.
The exact mathematical operations used to carry out KNN differ depending on the chosen distance metric. If you would like to learn more about how the metrics are calculated, you can read about some of the most common distance metrics, such as Euclidean, Manhattan, and Minkowski.
Why The Value Of K Matters
The main limitation when using KNN is that in an improper value of K (the wrong number of neighbors to be considered) might be chosen. If this happen, the predictions that are returned can be off substantially. It’s very important that, when using a KNN algorithm, the proper value for K is chosen. You want to choose a value for K that maximizes the model’s ability to make predictions on unseen data while reducing the number of errors it makes.

Photo: Agor153 via Wikimedia Commons, CC BY SA 3.0 (https://en.wikipedia.org/wiki/File:Map1NN.png)
Lower values of K mean that the predictions rendered by the KNN are less stable and reliable. To get an intuition of why this is so, consider a case where we have 7 neighbors around a target data point. Let’s assume that the KNN model is working with a K value of 2 (we’re asking it to look at the two closest neighbors to make a prediction). If the vast majority of the neighbors (five out of seven) belong to the Blue class, but the two closest neighbors just happen to be Red, the model will predict that the query example is Red. Despite the model’s guess, in such a scenario Blue would be a better guess.
If this is the case, why not just choose the highest K value we can? This is because telling the model to consider too many neighbors will also reduce accuracy. As the radius that the KNN model considers increases, it will eventually start considering data points that are closer to other groups than they are the target data point and misclassification will start occurring. For example, even if the point that was initially chosen was in one of the red regions above, if K was set too high, the model would reach into the other regions to consider points. When using a KNN model, different values of K are tried to see which value gives the model the best performance.
KNN Pros And Cons
Let’s examine some of the pros and cons of the KNN model.
Pros:
KNN can be used for both regression and classification tasks, unlike some other supervised learning algorithms.
KNN is highly accurate and simple to use. It’s easy to interpret, understand, and implement.
KNN doesn’t make any assumptions about the data, meaning it can be used for a wide variety of problems.
Cons:
KNN stores most or all of the data, which means that the model requires a lot of memory and its computationally expensive. Large datasets can also cause predictions to be take a long time.
KNN proves to be very sensitive to the scale of the dataset and it can be thrown off by irrelevant features fairly easily in comparison to other models.
Summing Up
K-Nearest Neighbors is one of the simplest machine learning algorithms. Despite how simple KNN is, in concept, it’s also a powerful algorithm that gives fairly high accuracy on most problems. When you use KNN, be sure to experiment with various values of K in order to find the number that provides the highest accuracy.






{kind=link}