
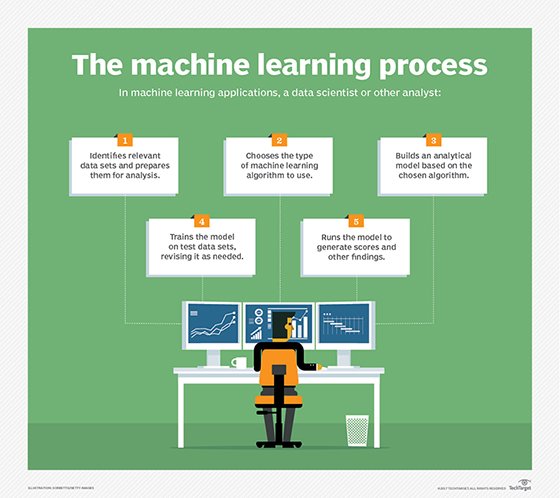
Model development is not one-size-fits-all — there are different types of machine learning algorithms for different goals and data sets. To navigate and rank specific algorithms is heavily dependent on which user role is using the algorithm and for what purpose. For example, the relatively straightforward linear regression algorithm is easier to train and implement than other machine learning algorithms, but may fail to add value in an enterprise that’s seeking to do more complex predictions.
Before diving into the complicated programming and vendor search, enterprises need to have a general understanding of model types and what they do best. The five following models range in user-friendliness and support different goals, but all are among the most popular and commonly used across enterprises.
1. Linear regression
First, and arguably the most popular type of machine learning algorithm, is linear regression. Linear regression algorithms map simple correlations between two variables in a set of data. A set of inputs and their corresponding outputs are examined and quantified to show a relationship, including how a change in one variable affects the other. Linear regressions are plotted via a line on a graph.
Linear regression’s popularity is due to its simplicity: The algorithm is easily explainable, relatively transparent and requires little to no parameter tuning. Linear regression is frequently used in sales forecasting and risk assessment for enterprises that seek to make long-term business decisions.
Linear regression is best for when “you are looking at predicting your value or predicting a class,” said Shekhar Vemuri, CTO of technology service company Clairvoyant, based in Chandler, Ariz. “The quintessential example is credit scoring, or will a student pass or fail a class — mostly answers that lots of enterprises need projected that come down to, ‘Is this going to happen or not?'”
2. Decision tree
A decision tree algorithm takes data and graphs it out in branches to show the possible outcomes of a variety of decisions. Decision trees classify response variables and predict response variables based on past decisions.
Decision trees are a visual, easily communicated method of mapping out decisions and results and are relatively accessible to citizen data scientists. Do you need to be able to traverse decisions and see how they would affect the end result? A decision tree algorithm maps that out and can even be used with incomplete data sets through their own predictive analytics.
Decision trees, due to their long-tail visuals, work best for small data sets, low-stakes decisions and concrete variables. Because of this, common decision tree use cases involve augmenting option pricing — from mortgage lenders classifying borrowers to product management teams quantifying the shift in market that would occur if they changed a major ingredient.
Decision trees remain popular because they are able to outline multiple outcomes and tests without requiring data scientists to deploy multiple algorithms, said Jeff Fried, director of product management for InterSystems, a software company based in Cambridge, Mass.
“Model development is not like software development. You rarely get to deploy the same model twice, because the factors are constantly changing, and it’s very hard to measure how well a model is truly doing, much less do regression testing,” Fried said.
3. Support vector machines
Support vector machines, or SVM, is a machine learning algorithm that internally analyzes a data set into classes to help with future classifications. Technically, SVM finds a line that separates training data into specific classes and maximizes the margins of each class in order to generalize future data into classes.
This algorithm works best for training data that can clearly be separated by a line — also referred to as a hyperplane. Nonlinear data can be programmed into a facet of SVM called nonlinear SVMs. But, with training data that’s hyper-complex — faces, personality traits, genomes and genetic material — the class systems become smaller and harder to identify and require a bit more human assistance.
SVMs are used heavily in the financial sector, as they offer high accuracy on both current and future data sets. The algorithms can be used to compare relative financial performance, value and investment gains virtually.
Companies with nonlinear data and different kinds of data sets are looking to SVM and automated services to help classify images, Vemuri said.
“As manufacturing companies build products, they’re taking high resolution images of the product. They also have quality assurance people who are annotating these images with manufacturing defects. Now, this company has a huge data set and database of images that also have some adaptations, [and want to] automatically identify some of these defects.”
4. K-means clustering
K-means algorithm is an iterative method of sorting data sets through defined clusters (K) and putting out the aforementioned clusters with input data attached and sectioned. In a K-cluster algorithm, sorting web results for the word civic will produce groups of search results for civic meaning Honda Civic and civic as municipal or civil and similar concepts.
K-means clustering has a reputation for accurate, streamlined groupings processed in a relatively short period of time, compared with other algorithms. K-means clustering is popular among search engines to produce relevant information and enterprises looking to group searcher intent by connotative meaning.
5. Apriori
The Apriori algorithm, based off the Apriori principle, is most commonly used in market basket analysis to mine item sets and generate association rules. The algorithms check for a correlation between A and B in a data set to generate a positive or negative correlation between products.
The Apriori algorithm is primed for sales teams that seek to notice which products customers are more likely to buy in combination with other products. If a high percentage of customers who purchase bread also purchase butter, the algorithm can conclude that purchase of A (bread) will often lead to purchase of B (butter). This can be cross-referenced in data sets and purchase ratios.
Apriori algorithms can also determine that purchase of A (bread) is only 10% likely to lead to the purchase of C (corn) — therefore informing marketing intentions and product placement strategies.
Besides sales functions, Apriori algorithms are favored by e-commerce giants, like Amazon and Alibaba, but are also used for searcher intent by sites like Bing and Google to predict searches by correlating associated words.







{kind=link}